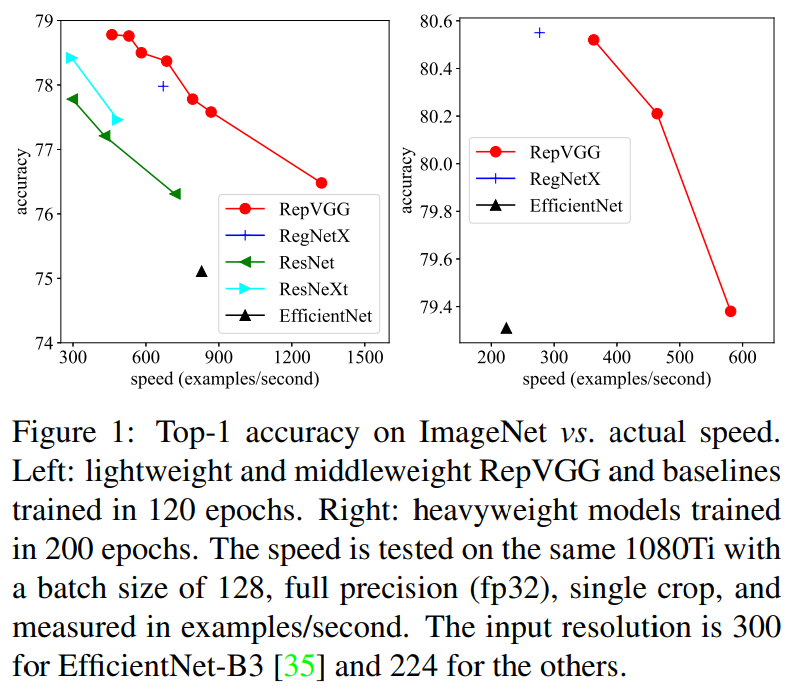
ACNet论文阅读
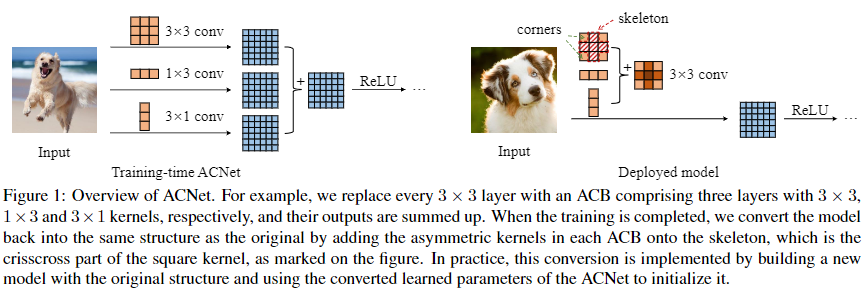
论文:ACNet: Strengthening the Kernel Skeletons for Powerful CNN via Asymmetric Convolution Blocks
作者:Xiaohan Ding , Yuchen Gu , Guiguang Ding , Jungong Han
录用情况:ICCV'2019
第一作者单位:Beijing National Research Center for Information Science and Technology (BNRist); School of Software, Tsinghua University, Beijing, China
本文是结构重参数化的第一篇文章,使用1D的卷积来增强方形卷积,并且在推理前进行结构重参数化,用这样的块替换先前的网络架构进行训练,或多多少的都在CIFAR和ImageNet上获得了提升,原因可能是1D卷积对旋转、翻转变换具有更好的鲁棒性以及。网络上已经有很多介绍具体方法的文章(知乎 - 【CNN结构设计】无痛的涨点技巧:ACNet),笔者在这里主要关注论文最后剪裁(pruning)实验,感觉还挺独特的。