
Non-local网络回顾
论文:Non-local Neural Networks
作者:Xiaolong Wang, Ross Girshick, Abhinav Gupta, Kaiming He
录用情况:CVPR'2018
第一作者单位:Carnegie Mellon University,Facebook AI Research
本文提出的Non-Local是捕获长距离信息的,这篇文章主要在视频分类任务上做实验(Kinetics, Charades),但在静态图像方面,也在COCO上进行了实例分割、检测和姿态估计的实验。
笔者认为,Non-Local在计算attention的方法上有所扩展,并在计算attention之前使用池化方法减小计算量之外,与self-attention没有什么不同的。
当然,在当时的情况下,Self-Attention还在NLP领域内玩,而且作者提出他们的insight来自于一种经典的图像去噪算法Non-local mean。
整体形式
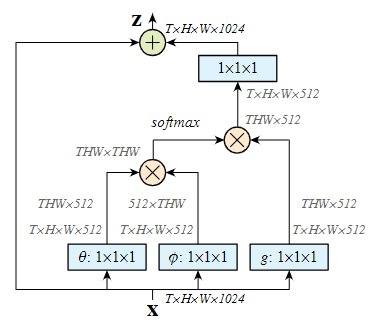
与Non-local mean一样的,作者希望将如下公式设计到网络结构中去: \[ \mathbf{y}_i=\frac{1}{\mathcal{C}(\mathbf x)}\sum_{\forall j}f(\mathbf x_i, \mathbf x_j)g(\mathbf x_j) \] 其中,\(\mathbf x\)是输入信号,\(\mathbf y\)是与之形状相同的输出信号,\(i,j\)是空间位置上的索引,\(f\)是度量相似度的函数,\(g\)是一种从源空间到度量空间的映射,\(\mathcal C(\mathbf x)\)是归一化项。其含义可以理解为,对于每个位置上的输入信号,都与空间上其他位置的信号计算一个相似度,作为权值,计算在全局上的加权平均作为输出。
相比之下,卷积操作,一个像素只能与其邻域范围内的像素直接相关;而全连接(即矩阵乘法)也是一种全局的加权,但是其权重是在训练集中学习到的,而非Non-local这样输入适应的,并且全连接层限制了输入的形状。
细节设计
作者令\(g(x)=W_g\mathbf x_j\),没有做过多的讨论。对于\(f\)和\(\mathcal C\),作者给出了四种形式:
- Gaussian:\(f(\mathbf x_i, \mathbf x_j)=e^{\mathbf x_i^T \mathbf x_j}\),\(\mathcal C(\mathbf x)=\sum_{\forall j}f(\mathbf x_i, \mathbf x_j)\),在实现的时候,就是完成点积之后添加一个Softmax层;
- Embedded Gaussian:\(f(\mathbf x_i, \mathbf x_j)=e^{\theta(\mathbf x_i)^T \phi(\mathbf x_j)}\),\(\mathcal C(\mathbf x)=\sum_{\forall j}f(\mathbf x_i, \mathbf x_j)\),其中\(\theta\)和\(\phi\)也都是线性映射;这种情况就是没有除以\(\sqrt d\)的self attention了;
- Dot product:\(f(\mathbf x_i, \mathbf x_j)=\theta(\mathbf x_i)^T \phi(\mathbf x_j)\),\(\mathcal C(x)=N\),其中\(N\)是空间位置的数量,对于2D,就是HxW,对于3D,就是TxHxW,这里使用常数作为归一化是为了简单;
- Concatenation:\(f(\mathbf x_i, \mathbf x_j)=\text{ReLu}(\mathbf w_f^T[\theta(\mathbf x_i), \phi(\mathbf x_j)])\),\(\mathcal C(x)=N\);
同样的,作者引入了残差连接,即希望学习的\(\mathbf y\)是一个残差,整个Non-local块表示为: \[ z_i=W_z\mathbf y_i+\mathbf x_i \] 按照bottleneck的设计,同样是为了减少参数量,度量时的通道数减少为输入输出的一半;此外,还可以引入池化操作进一步减少计算量,用Embedding Gaussian中的式子表示,为\(y_i=\frac{1}{\mathcal C(\hat{\mathbf x})} f(\mathbf x_i, \hat{\mathbf x}_j)g(\hat{\mathbf x}_j)\),其中\(\hat{\mathbf{x}}_j\)是\(\mathbf x_j\)下采样的结果。
实验
原作的实验关注了视频理解任务,因为该论文现在不算新了,这里就不再赘述。在MMSegmentation里有一个把Non-local用在decoder head中的分割模型,可以参考。