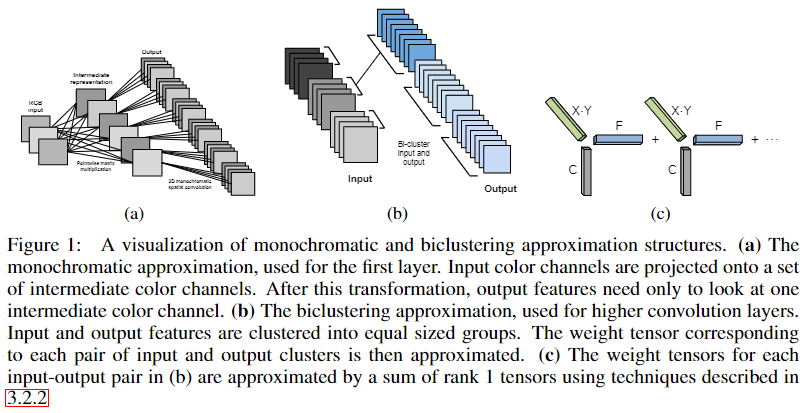
学习结构化稀疏:精度与速度的双赢?
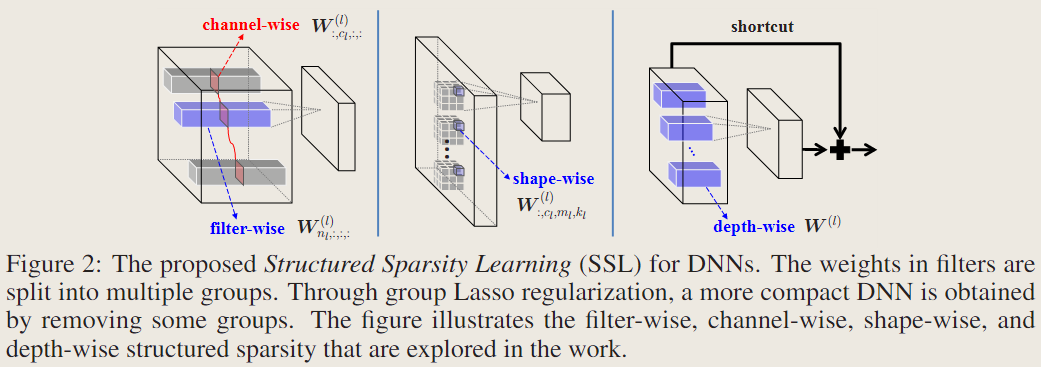
论文:Learning Structured Sparsity in Deep Neural Networks
作者:Wei Wen, Chunpeng Wu, Yandan Wang, Yiran Chen, Hai Li
一作单位:University of Pittsburgh
录用情况:Neurips'2016
本文通过添加在滤波器数量、通道、形状维度以及深度上的group lasso正则化,让模型学习到结构化稀疏,后再微调;实验表明,这种结构化稀疏不需要很大的稀疏率就可以在多种设备上产生可观的加速效果,甚至还能减轻过拟合从而提升性能。